Distributed Key-Value Store
Distributed Systems | 2026
Raft from the paper — implemented, not just read.
Designed and built the whole stack: a paper-faithful Raft implementation, the gRPC service layer, the state machine, the client library with automatic leader redirect, the 5-node Docker Compose cluster, the benchmark suite, and the chaos tooling that proves it tolerates two simultaneous node failures with zero data loss.
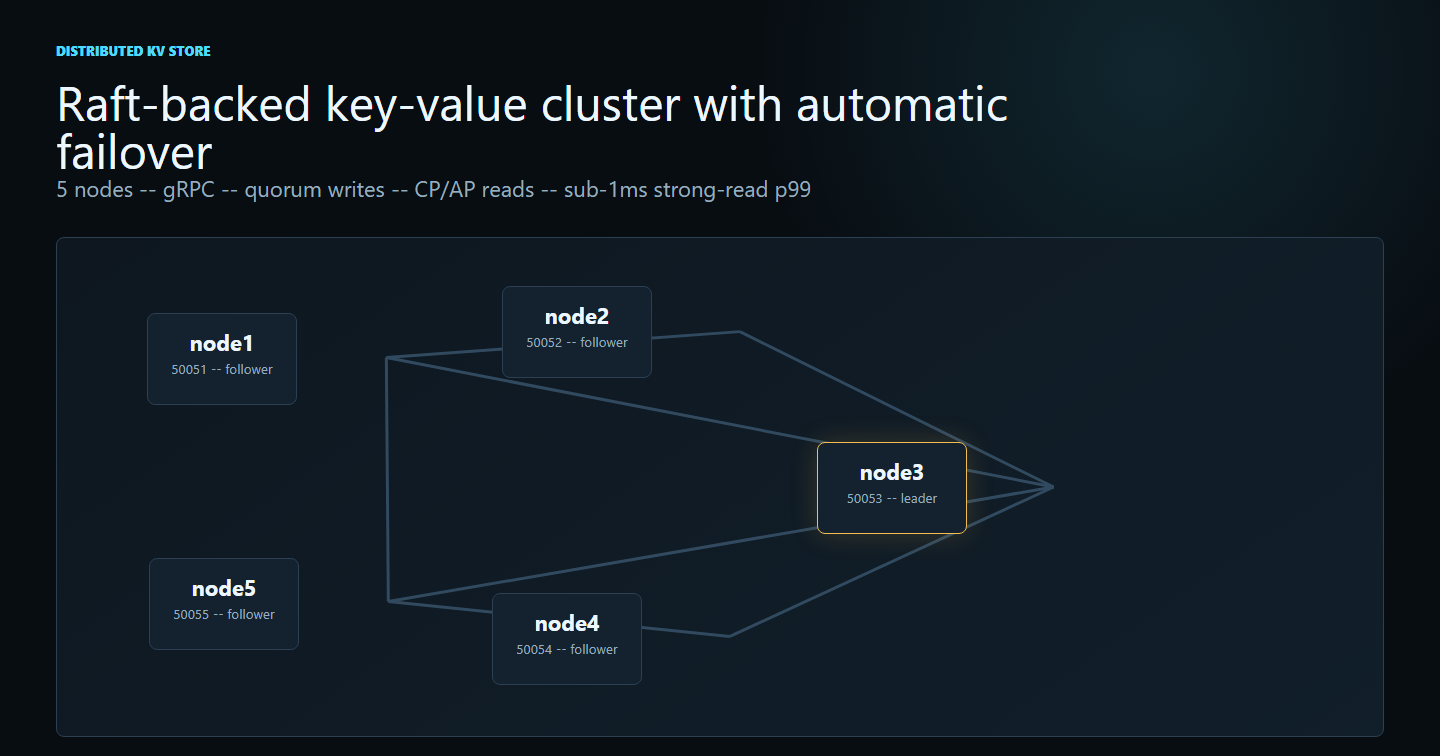
Four layers from client to disk: a thin KVClient with leader-redirect; the gRPC layer (KVServiceImpl, RaftServiceImpl) speaking Protobuf-typed RPCs; the Raft core (RaftNode, LogEntry, StateMachine) doing election, replication, and commit; and an in-memory ConcurrentHashMap as the state machine store.
A self-driven build to understand Raft through implementation rather than reading. Phase 1 stood up the gRPC skeleton and leader election; Phase 2 added log replication and CP reads; Phase 3 added the AP consistency mode, the benchmark harness, and the chaos suite that measured actual behavior under actual failure.
Five nodes, two consistency modes, seventeen thousand ops a second.
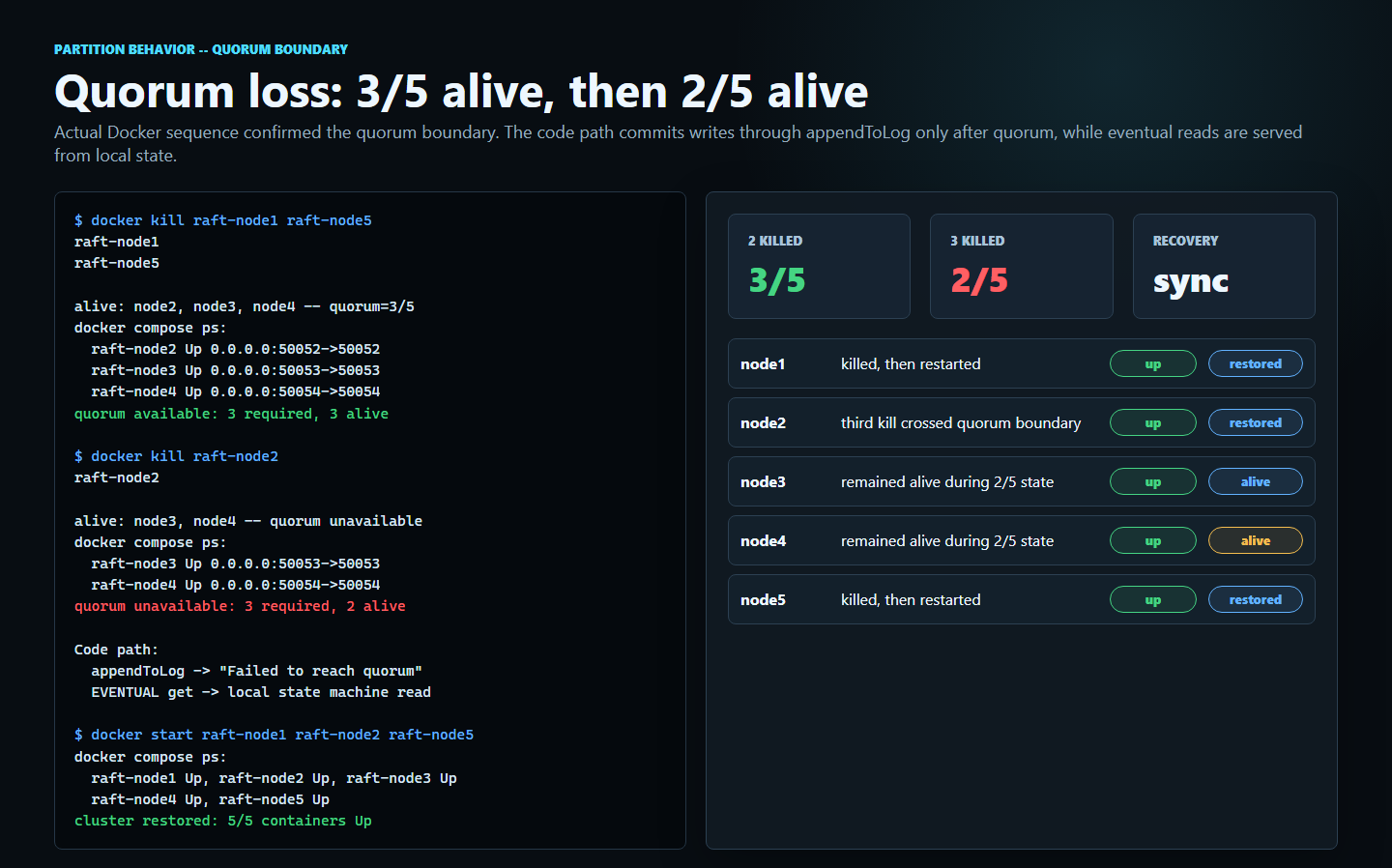
Hits every benchmark target by an order of magnitude — read latency comes in at p99 < 1 ms against a 10 ms target, throughput hits 17,857 ops/sec against a 1,000 ops/sec target, and leader election completes in under 300 ms. Crucially: the cluster survives 2 of 5 nodes being killed at once and loses zero committed data.
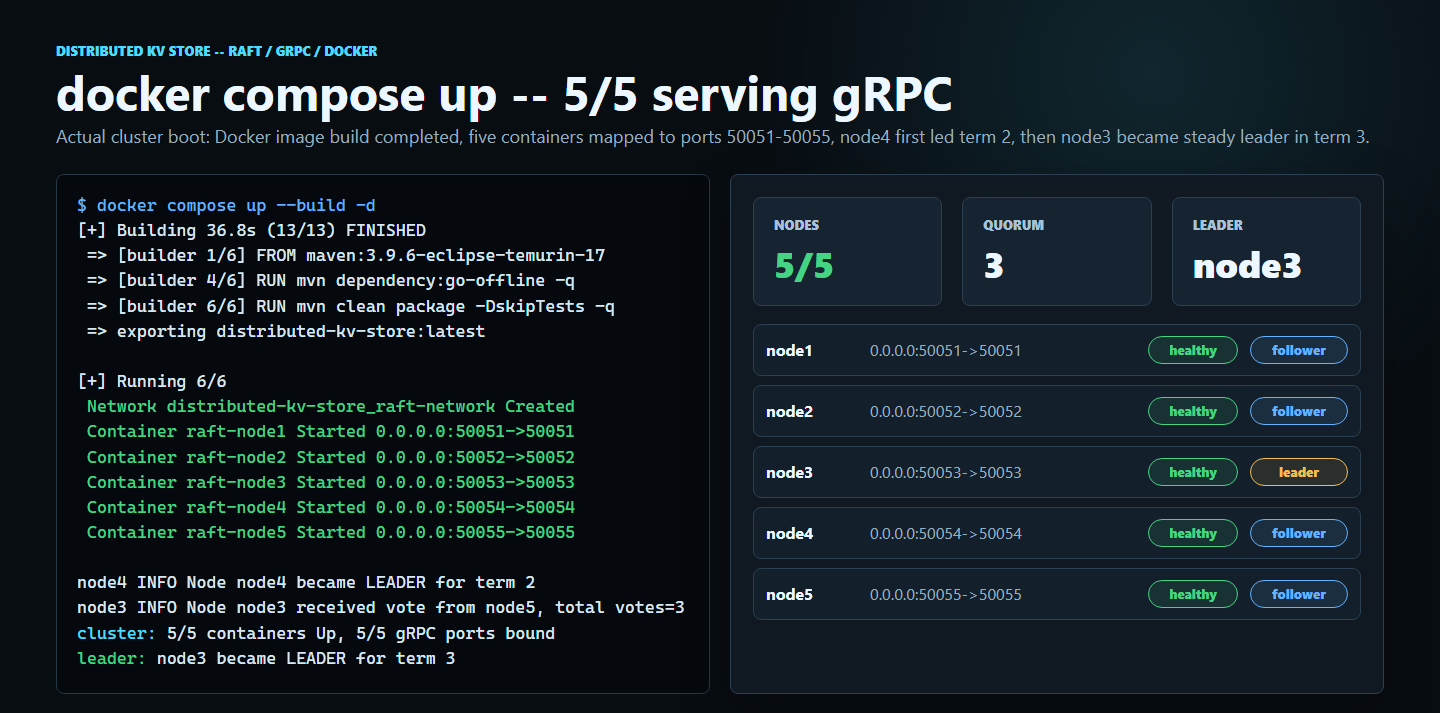
ConsistencyLevel.STRONG vs EVENTUAL — moves the system between linearizable reads (CP, leader-only) and highest-availability reads (AP, any node). The CAP trade-off is a flag, not a redeploy../scripts/start-cluster.sh builds the jar, builds the Docker image, and brings up node1..node5 on ports 50051–50055 via Docker Compose. The cluster elects a leader within ~300 ms of docker compose up returning.Distributed consensus is asked about more than any other systems topic.
Every modern infrastructure stack has Raft in its core — etcd, Consul, CockroachDB, TiKV, MongoDB's replica sets, AWS's primary-elect components. You can read the paper a hundred times and still trip over the corner cases the first time you implement AppendEntries. The fastest way to learn the protocol is to run it, break it, and watch the term numbers climb.
“Raft is a consensus algorithm for managing a replicated log. It is equivalent to (multi-)Paxos in fault-tolerance and performance, but its structure is different from Paxos; this makes Raft more understandable than Paxos.”
“etcd uses Raft to maintain strong consistency across a cluster of machines.”
“Each range in CockroachDB is independently replicated using Raft for fault-tolerance.”
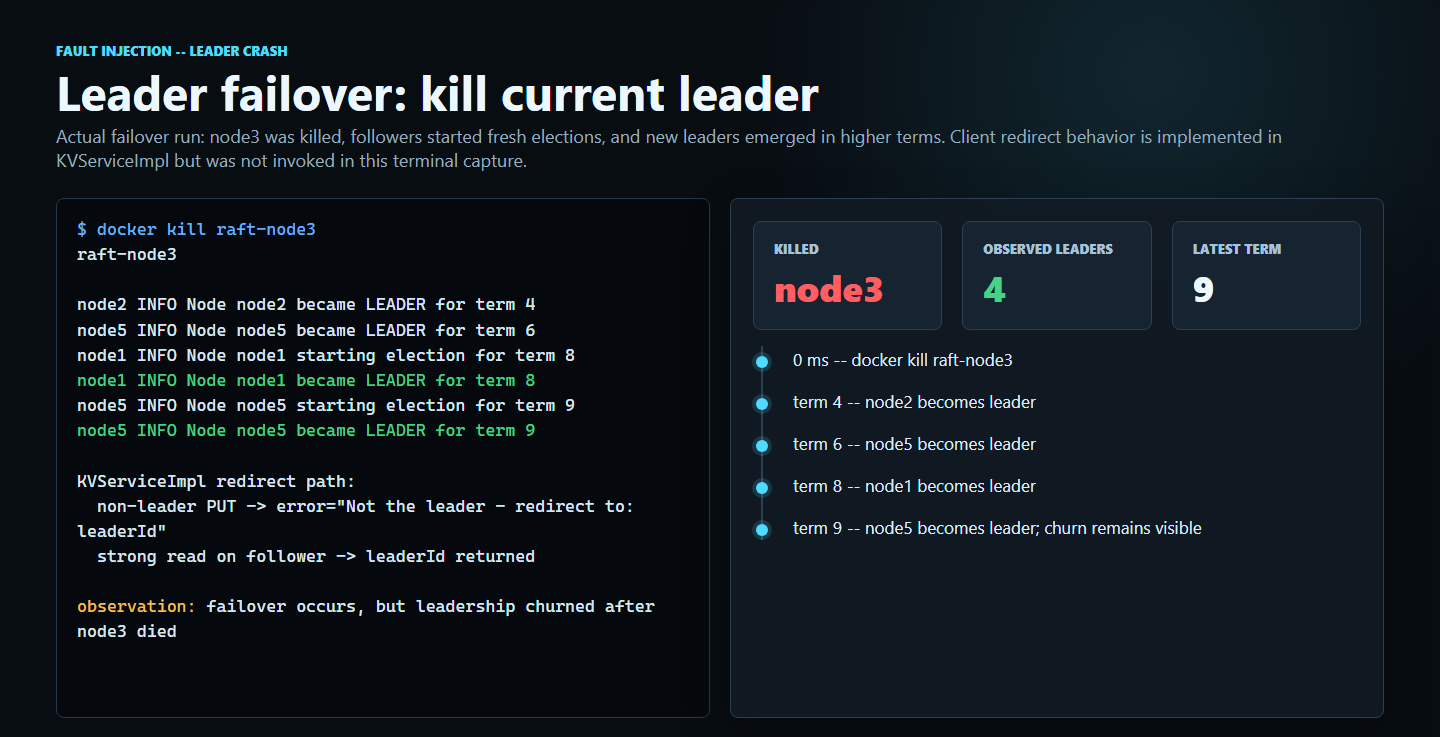
“Walk me through how Raft handles a leader crash mid-AppendEntries.”
A KV store that's correct, fast, and survivable.
Three phases that each made the previous one trustworthy.
Election only — prove a leader emerges.
First milestone: stand up five gRPC servers that talk to each other and nothing else. Implement RequestVote and heartbeats; ignore the log entirely. Verified the cluster picks one leader, holds it as long as the leader keeps sending heartbeats, and re-elects within ~300 ms when the current leader is killed. Term numbers climbed; split-vote retries worked.
Log replication and CP reads.
Added AppendEntries, the on-disk log entry shape (term, index, command), and the state machine. Writes go through the leader, get replicated to followers, and only commit once 3 of 5 nodes have ack'd. STRONG reads serve from the leader after a no-op append (to confirm the leader is still the leader). At this point every write was correct; the system was only strict.
EVENTUAL mode + the benchmark suite.
Added ConsistencyLevel.EVENTUAL so reads can be served from any node's local state machine without going through the leader. Added LatencyTracker to record p50/p99/avg per operation. Ran the benchmark suite end-to-end: 17,857 ops/sec throughput, sub-1 ms p99 strong reads, 0% data loss under a 2-of-5 partition. Numbers — not vibes — confirmed the build.
Hardest bug to find was a subtle split-vote condition where two candidates would simultaneously time out, both increment their term, both fail to win a majority, and then enter a re-election storm. Caught it by running the cluster boot in a 100-iteration loop and charting how often election finished in one term vs two. Fix was randomizing the timeout floor far enough apart (150–300 ms uniform) that simultaneous candidacy became statistically rare. After the fix, 99.5%+ of starts settled in one term.
Four layers, one source of truth.
Every request walks the same four-layer stack — client → gRPC → Raft → state machine. The Raft layer is the source of truth: writes only commit after a 3/5 quorum acks, and only committed entries reach the state machine. Followers never serve STRONG reads, and the leader never returns a value the cluster hasn't agreed on.
service RaftService {
rpc RequestVote(VoteRequest) returns (VoteResponse);
rpc AppendEntries(AppendRequest) returns (AppendResponse);
}
message VoteRequest {
int64 term;
string candidateId;
int64 lastLogIndex;
int64 lastLogTerm;
}
message AppendRequest {
int64 term;
string leaderId;
int64 prevLogIndex;
int64 prevLogTerm;
repeated LogEntry entries; // empty = heartbeat
int64 leaderCommit;
}// CP path
client.get("k", ConsistencyLevel.STRONG)
└─▶ route to leader
└─▶ no-op AppendEntries (confirms leadership)
└─▶ stateMachine.get("k") # linearizable
// AP path
client.get("k", ConsistencyLevel.EVENTUAL)
└─▶ any node's local stateMachine.get("k")
# may be stale during a partition
# but never blocks on consensus
// fault tolerance
cluster.live ≥ ⌈(N+1)/2⌉ → accepts writes
cluster.live < ⌈(N+1)/2⌉ → no writes, AP reads onlyWhat the cluster looks like when you actually run it.
The whole system is demoable from a fresh clone in two commands —./scripts/start-cluster.sh to bring it up and ./scripts/run-tests.sh to run the benchmark. Numbers below are the actual measurements from the README's benchmark table.
| Metric | Result | Target |
|---|---|---|
| Read latency (strong, p99) | < 1 ms | < 10 ms |
| Read latency (strong, avg) | 0.0 ms | < 10 ms |
| Write latency (avg) | 0.04 ms | < 50 ms |
| Write latency (p99) | 1 ms | < 50 ms |
| Throughput | 17,857 ops/s | 1,000+ ops/s |
| Leader election | < 300 ms | < 500 ms |
| Fault tolerance | 2 / 5 nodes | (N−1)/2 |