METY Legal Chatbot
AI / Full Stack | 2026

What it is, and why I built it.
Sole engineer on the QnA backend, FSPR knowledge-profiling system, rolling summarization, document-generation feature, and production architecture across 7 sprints on a 6-person team. Rebuilt a 6-node LangGraph pipeline into a privacy-first 5-node topology, cut per-query LLM cost 82% ($0.024 → $0.0044), and added implicit Most Critical Gap targeting on every response with zero user-facing latency.
Two-layer architecture: Django owns state and data, FastAPI is stateless and has zero database credentials. The 5-node LangGraph pipeline runs RAG → Extraction → Anonymization → Reasoning → Formatter; FSPR profiling and rolling summarization fire as background daemon threads after every response so the user never waits for them.
Sponsor engagement with MyEdMaster — they had already beaten ChatGPT on a benchmark with their health chatbot and wanted the same result for a legal product. Shipped end of May 2026, handed to a continuation team, demoed at the ASU SER517 Innovation Showcase. No public deployment — IP belongs to MyEdMaster under signed NDA.
METY in three modes, one knowledge profile.
Rebuilt a 6-node LangGraph pipeline into a privacy-first, cost-optimized 5-node architecture that serves personalized legal guidance across three user modes, cutting per-query LLM cost by 82% while adding implicit FSPR knowledge profiling on every message with zero user-facing latency impact.
LegalChatState dict and writes back partial updates that LangGraph merges automatically.Legal help is inaccessible for most people.
Options were: pay $300/hour for a lawyer, search generic legal websites that assume zero or complete knowledge, or use a generic chatbot that gives the same answer regardless of background. No existing tool profiled legal knowledge at an individual level and targeted responses to close specific knowledge gaps. LegalZoom and Rocket Lawyer are form-fillers, not educators.
“We are not your lawyers. Advice here is general. Your situation may be completely different.”
“A big thanks to our PR person Tony Berry who got our latest chatbot success story (our health chatbot greatly outperformed ChatGPT) featured in 30 newspapers.”
“86% of civil legal problems reported by low-income Americans receive inadequate or no legal help.”
“Long-session coherence is the recurring developer pain — context windows blow out, history gets truncated.”
“There's no application-layer way to signal what a user already knows.”
Six engineers, seven sprints, and six hard constraints.
Three pivots that earned every dollar back.
Killing the clarification node.
The original pipeline had a dedicated clarification node that ran before reasoning on every message, using GPT-4o to decide whether to ask a clarifying question — but it fired unconditionally, even when the query was completely clear. Removed entirely in Sprint 6, flattening the pipeline to 5 nodes. Lawyer-style probing was rebuilt inline in the reasoning prompt instead. This was the single biggest cost reduction — one full GPT-4o call eliminated per message.
submit_self_assessment running 4 LLM calls per submission.
The self-assessment evaluation was running KB fetch, AI evaluate call, and MongoDB persist inside a for-loop iterating over the four FSPR dimensions. Each operation executed four times per submission. Caught during Sprint 5 testing when the API bill for a single session was 4× expected. All three operations moved outside the loop — KB fetched once, evaluation called once with all four dimensions passed together, persisted once.
Document generation producing anonymized names.
The first document-generation attempt produced PDFs with fictional party names because conversation_summary (which had passed through the anonymization node) was used as context. Fix: pull raw message content directly from the Message model before anonymization runs, bypassing the anonymized summary entirely. Real names appeared immediately.
In Sprint 7 testing, ready_to_generate kept returning false at the Django layer even though the AI service was correctly setting it to true. Three hours of debugging traced it to the LLM wrapping its JSON response in markdown code fences (```json), causing the JSON parser to fail silently and fall through to a raw-text fallback that had no ready_to_generate field. Fix: regex strip of code fences before JSON parsing plus a JSON extraction fallback using re.search(r'{[\s\S]*}', raw) for mixed-content responses.
Conditional clarification branch firing GPT-4o on every message regardless of necessity.
RAG → Extraction → Anonymization → Reasoning → Formatter. Lawyer-style probing inline in the reasoning prompt.
~$0.024 / message · 3 full GPT-4o calls (reason + clarify + history-summarize)
~$0.0044 / message · 1 GPT-4o (reason) + 2 GPT-4o-mini background (FSPR + summarize)
State, pipeline, and the algorithms behind it.
The full request lifecycle from browser to response — Django preprocesses every message (sanitize via bleach, fetch context via tiktoken token count, build user_context), calls FastAPI /query, the 5-node LangGraph pipeline runs, the response returns, Django persists the LLM message to MongoDB, and two daemon threads fire — one for FSPR inference, one for token-aware summarization. Both call GPT-4o-mini and never block the user.
# Signals (LLM classifies which dim is most revealed) Know–Know → 0.80 Know–Don't Know → 0.40 False Knowledge → 0.20 Omission → 0.30 # EMA update per dimension new_score = current × 0.7 + signal × 0.3 # Priority weights for Most Critical Gap False Knowledge 0.40 Omission 0.30 Know–Don't Know 0.20 Irrelevant Knowledge 0.10
LLM1 classify_domain()
│
├──┐ (parallel)
LLM2 generate_kb() ──┐
LLM4 generate_examples() ──┤
│ │
│ audit (disabled by default)
│
└─▶ 4 parallel dimension evaluators
↑
single KB fetch · single persist
(moved out of the for-loop in V2)Three modes, one cohesive product.
The product shipped as three entry points under one knowledge profile. Below are the three frames that show the end-to-end flow, plus a short demo recorded from the sponsor-handoff build.
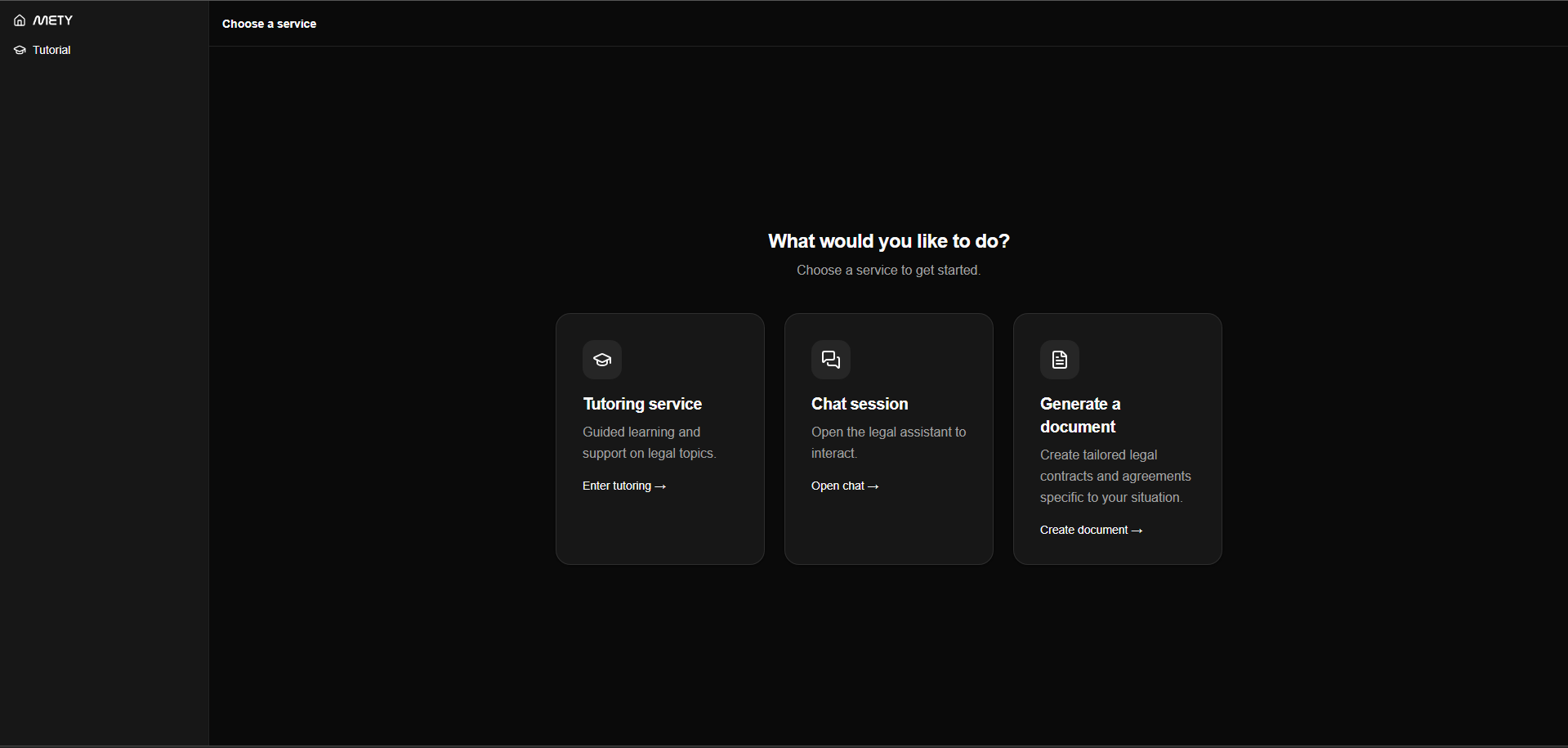
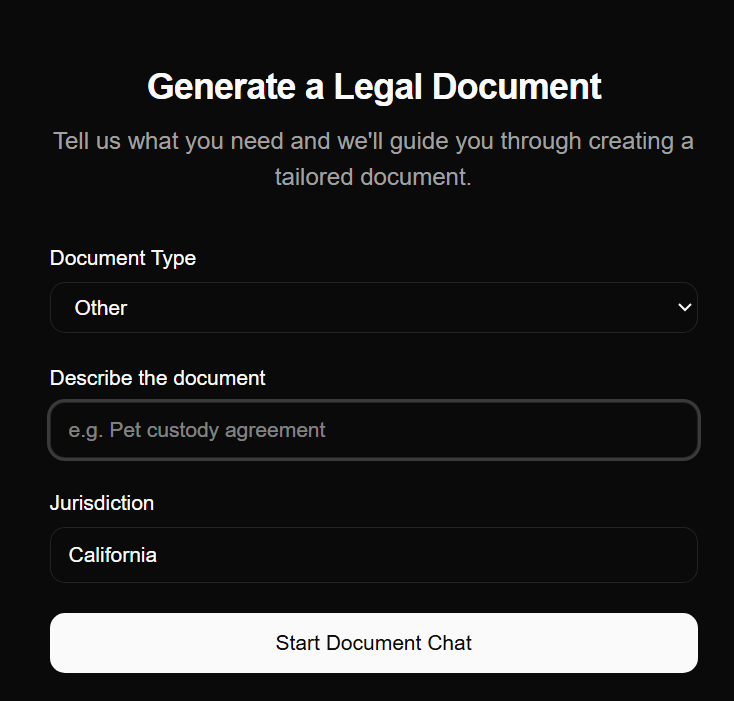
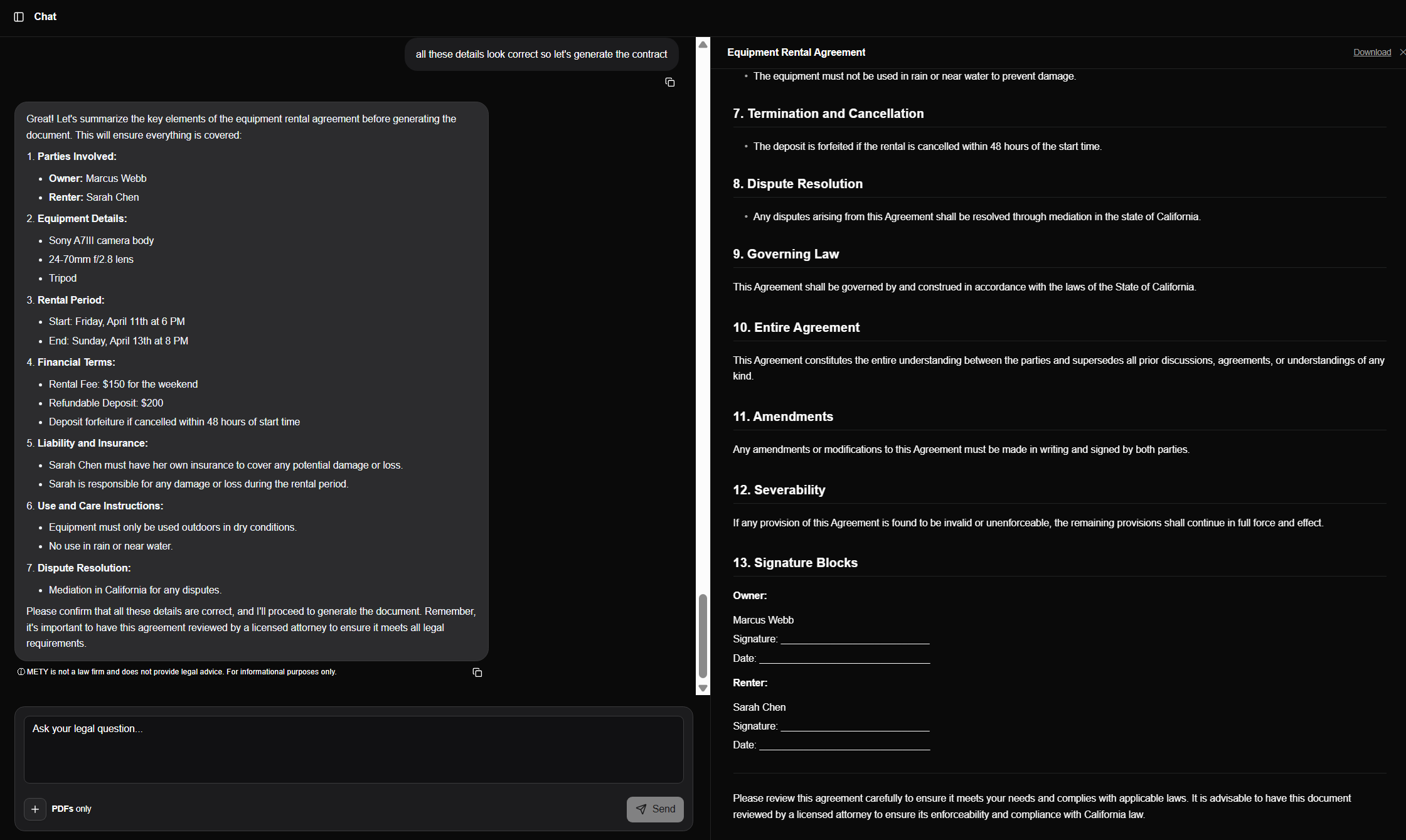
Intake-as-form, not free text. The user picks a document type, describes what they need in a sentence, confirms jurisdiction, and the chat takes over — lawyer-style probing, targeted follow-ups, and a context-aware draft that updates in place. Document chats are saved separately from regular legal chats so a user can return weeks later, find the in-progress NDA, and continue exactly where they left off.
Refresh recoveryOn reload, React state is lost — a useEffect on chatId calls getDocuments and rehydrates the split panel from MongoDB if a draft exists for that chat.
LaunchDelivered to MyEdMaster end of May 2026, handed to continuation team. Demoed at the ASU SER517 Innovation Showcase. No public deployment — IP belongs to MyEdMaster.
What worked, what I'd change.
Worked
Every debugging session, rebuild, and feature addition benefited from the AI service holding no state. Restart the container and nothing breaks. It looked like over-engineering in Sprint 2 and paid off in every sprint after.
Returning answer, detected_topics, confidence_delta, ready_to_generate, and document_context in one call eliminated what would have been 4-5 separate LLM calls per message and made the entire pipeline observable in LangSmith.
FSPR and summarization fire after the HTTP response with zero user-facing latency. close_old_connections() discipline was established early so no DB connection issues.
Would change
The fspr_update_in_progress boolean flag works but isn't production-safe — cross-process race conditions are only partially prevented. Celery would have given proper coordination, retries, and monitoring.
A bare user_id in the URL path inherited to every new endpoint. Retrofitting proper auth now would require touching every view and every frontend API call.
Prompts changed in every sprint with no way to A/B test or roll back. A version field on prompt constants and LangSmith experiment tagging would have made prompt iteration data-driven instead of intuition-driven.
Anonymization was the source of every weird bug. I expected it to be a straightforward privacy layer. What I didn't expect was how many features silently depended on whether they were reading anonymized or raw text — document generation used the anonymized summary and produced fictional names; FSPR inference passed anonymized LLM responses to the evaluator; the reasoning prompt received anonymized history that then produced responses with placeholder names. Every feature that touched persisted text had to be individually audited. Anonymization isn't a node decision — it's a data-provenance question that affects every field in every model.