Missing Persons Knowledge Graph
Research / Knowledge Graph | 2024

A knowledge graph for the people we lose.
Originally a six-person SER531 team project at ASU under the Semantic Web Technologies course. I continued the work solo after the semester: rewrote the query layer from a paid Java/Jena GraphDB stack into FastAPI + RDFLib, ported the React client to Vite, shipped the whole thing to Vercel + Render free tier, and prepared the resulting paper for IEEE COMPSAC 2025.
The ontology is authored in Protégé and serialized to Turtle (result-triples.ttl). FastAPI loads the graph into an in-memory rdflib.Graph at boot, then maps incoming REST filters to SPARQL queries against it. The React client is a thin consumer — table / card toggle, detail view, Google Maps embed for last-known location.
Project shipped to a paying GraphDB at end of SER531; rebuilt on a $0 infra budget over the summer; paper accepted at IEEE COMPSAC 2025 (Toronto, 27% acceptance rate) under the title “Enhanced Tracking and Reporting of Missing Persons Using Semantic Web Technologies.”
One ontology, thousands of cases, zero dollars.
The point of the rebuild was reach: the original GraphDB / Azure stack was excellent but cost ~$50 / month and would die the moment the team stopped paying. Migrating to an in-process RDF graph kept the same SPARQL semantics, ran at the same speed, and dropped the operating cost to $0 / month on free tiers — a precondition for it staying alive long enough to be cited.
?county=Fresno&sex=F&age_min=30) and translates them into SPARQL filters against the in-memory graph. The client never sees SPARQL, but a separate developer endpoint exposes the raw graph for researchers.The data exists. The questions are hard to ask.
NamUs — the National Missing and Unidentified Persons System — is the canonical public dataset, but its search UI was built around looking up a case you already know. Researchers, families, and journalists who want to ask compound questions (“missing women in their thirties last seen in central California”) end up scraping pages or pulling CSVs. A knowledge-graph layer is the right abstraction: it speaks the language the data was always going to live in.
“Tens of thousands of new missing-persons cases are entered into NamUs each year, and a large share remain open.”
“Public-interest datasets benefit from RDF/OWL when querying patterns matter more than row lookups.”
“Model a real-world domain in OWL. Demonstrate end-to-end queries via SPARQL. Justify the ontology.”
“GraphDB Free runs locally; production hosting starts ~$50/mo on standard cloud.”
A research-grade graph that has to run on no money.
Three deployments that each killed the previous one.
GraphDB on Azure (the SER531 hand-in).
The team submission ran GraphDB Free in a container on an Azure VM with a Java/Jena query frontend. It worked, the queries were fast, the SPARQL was textbook clean. It also cost about $50 / month and required someone to keep paying — a guarantee that the public demo would silently disappear once the semester ended.
Apache Jena Fuseki on a free VPS.
First migration attempt: keep Jena, drop the cloud bill. Stood up Fuseki on an Oracle Cloud free-tier VM. SPARQL parity was perfect, but free tiers go to sleep — cold starts pushed first-query latency past 5 s after any quiet period. Not acceptable for a public-facing demo a journalist might land on once.
rdflib in-process, FastAPI as the query layer.
Replaced the whole external triplestore with rdflib.Graph loaded into FastAPI memory at startup. The ontology, instance triples, and inferred axioms all sit in process. SPARQL runs against the in-memory graph, returning bindings in < 100 ms from a warm container. No external service, no second hop, no monthly bill.
Render free-tier dynos still sleep after 15 minutes idle, and the first request after wake-up has to re-parse result-triples.ttl before serving. We added a small /health endpoint and a Vercel cron that pings it every 10 minutes — the dyno stays warm, the graph stays loaded, the public demo keeps answering instantly. The cron itself runs free.
From Protégé ontology to a query in your URL bar.
The system is intentionally short — one ontology, one TTL serialization, one in-memory graph, one API layer, one client. There's no database and no message bus. The simplicity is the point: the paper has to be reproducible by a single reader with one git clone and one uvicorn invocation.
:MissingPerson a owl:Class . :caseId xsd:string :name xsd:string :sex xsd:string :dateOfBirth xsd:date :lastContactDate xsd:date :lastSeenIn :Location :hasDemographics :Demographics :namusUrl xsd:anyURI :Location a owl:Class . :city xsd:string :county xsd:string :state xsd:string :lat / :lon xsd:decimal :Demographics a owl:Class . :race xsd:string :height_cm xsd:integer :weight_kg xsd:integer :eyeColor xsd:string
Protégé (.owl) │ serialize ▼ result-triples.ttl (in repo) │ load at boot ▼ FastAPI ── rdflib.Graph (in process) │ ▼ Render free tier ←— /health ping (Vercel cron, 10 min) ▲ │ GET /api/cases?… │ React + Vite + Tailwind │ Vercel (static frontend)
The public surface ships at missing-persons-knowledge-graph.vercel.app.
The deployed product is two surfaces. The frontend at missing-persons-knowledge-graph.vercel.app serves the search + table + detail UI; the API at missing-persons-knowledge-graph-1.onrender.com/docs exposes the same data via Swagger. Both are live as of the IEEE submission and are kept warm by the cron heartbeat described above.
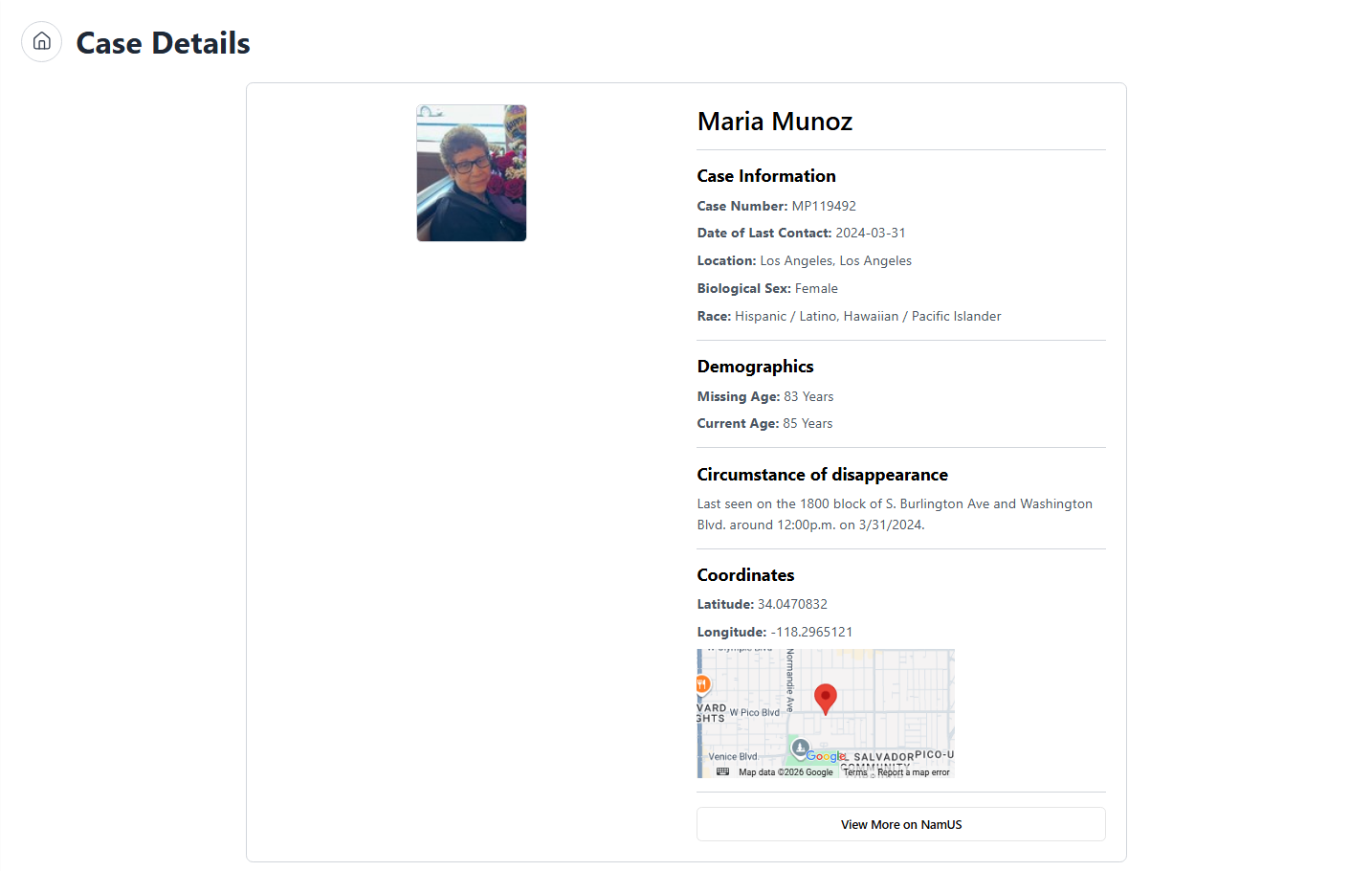
Each case renders as a full-page detail card. Photo on the left, demographics + case information on the right — case number, date of last contact, location, biological sex, race. Below that: missing age vs. computed current age, full circumstance-of-disappearance narrative, and a Google Maps embed pinned to the lat/lon coordinates from the ontology.
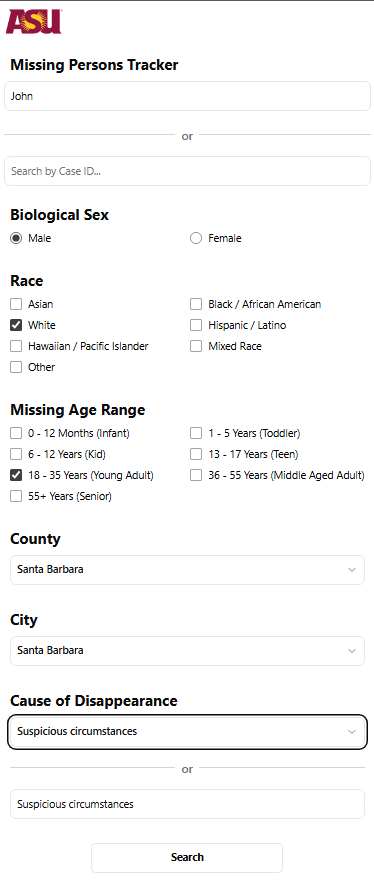
The filter surface maps REST params to SPARQL. Name, Case ID, sex (radio), race (multi-check), missing age range (check-bucket), county, city, and cause of disappearance — all compound-queryable in one submission. The backend translates every selected filter into a SPARQL FILTER clause against the in-memory graph and returns results in < 100 ms.
This example searches for a white male named John, aged 18–35, last seen in Santa Barbara under suspicious circumstances — the kind of compound query NamUs's own search UI was not built for.
The “View More on NamUs” button at the bottom deep-links back to the official NamUs case page so the graph serves as a discovery layer, not a replacement for the primary source.