PixelDrive: Road Scene Segmentation
Computer Vision | 2025



Three segmentation models, one honest mIoU.
Inherited a partially-working baseline notebook for road-scene segmentation on the Lyft / Udacity Carla dataset. Audited every line — fixed seven correctness bugs (including a broken mIoU metric, a wrong-axis mask decode, and a softmax / logits mismatch in the loss), then trained and benchmarked three architectures head-to-head: U-Net, SegNet, and DeepLabV3+. Picked the winner, packaged it as a Gradio app, and shipped it as a public Hugging Face Space.
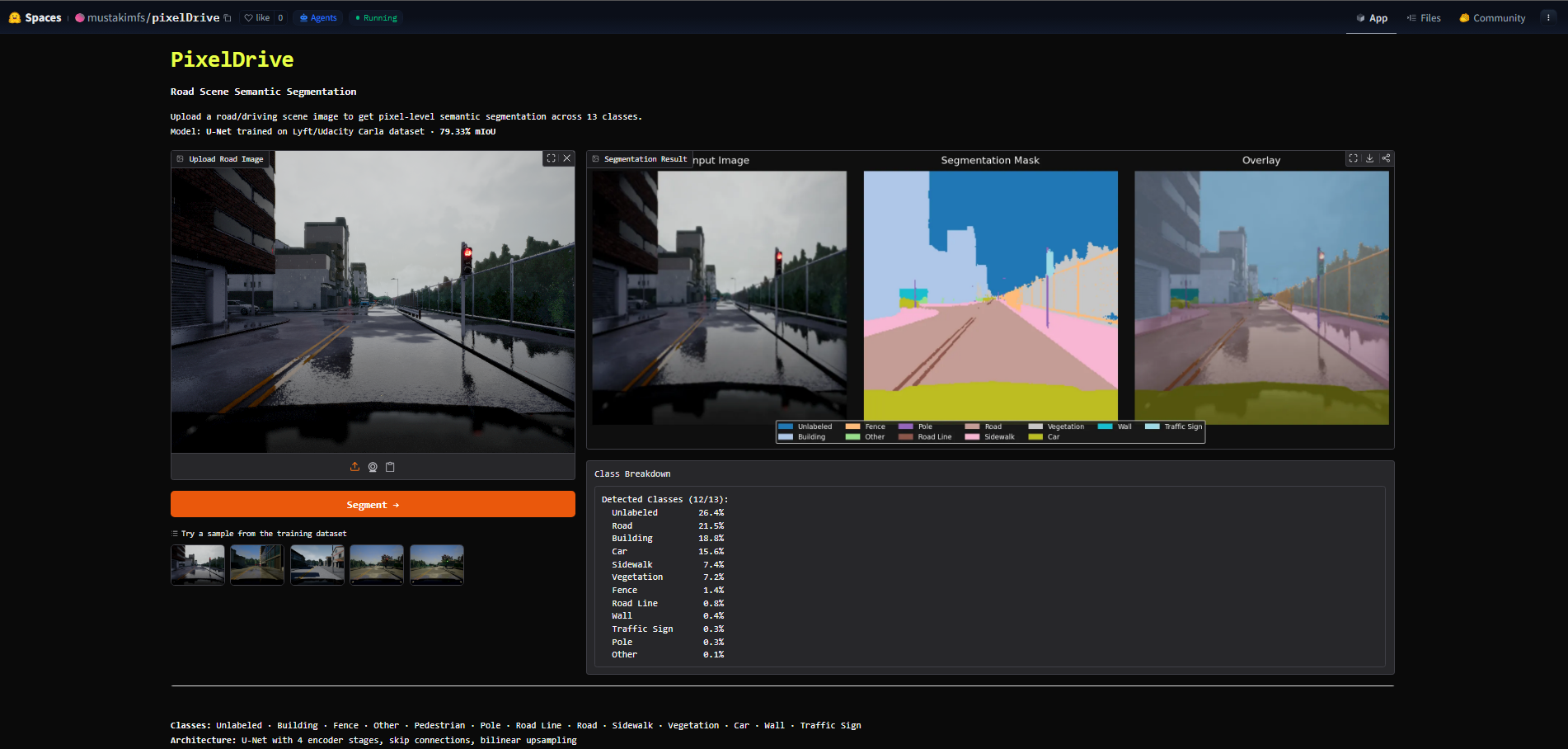
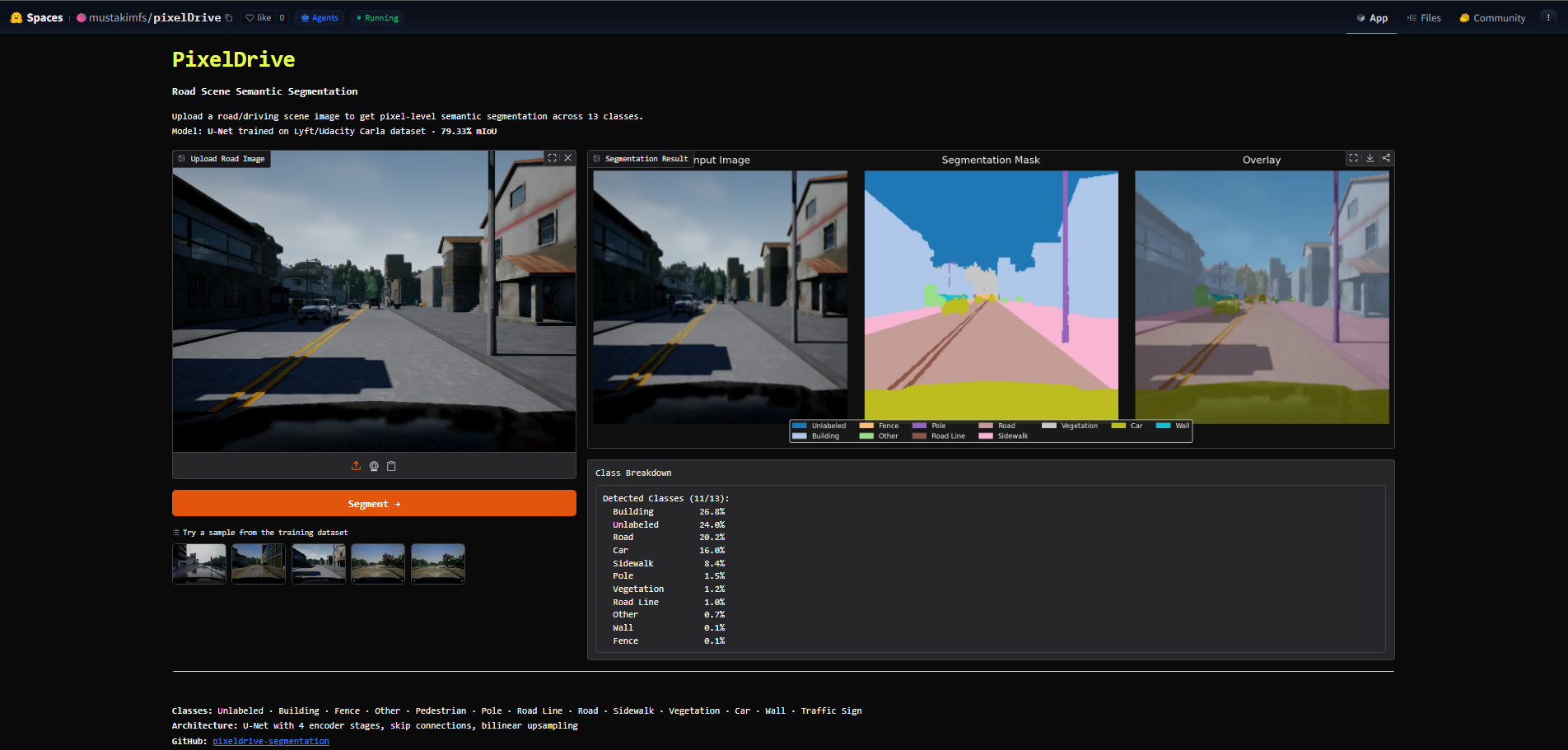
One Jupyter notebook is the source of truth — dataset prep, three model definitions, training loops, evaluation, and per-class IoU tables. The deployed Space loads the best-checkpoint unet_best.keras at startup and serves a three-panel inference UI (Input · Mask · Overlay) with a live class-percent breakdown.
Lives at huggingface.co/spaces/mustakimfs/pixelDrive. The full training notebook is in the repo — anyone can clone, retrain, and verify the numbers.
Pick the model that actually wins on the metric you reported.
The point of the project wasn't just to train a segmenter — it was to get to a number you could trust. The starting codebase reported a great-looking mIoU that fell apart under audit, so the first half of the project was fixing the metric, the loss, and the mask decode. Once the numbers became honest, the three-architecture comparison settled cleanly on U-Net at 79.33% mIoU.
huggingface.co/spaces/mustakimfs/pixelDrive runs the U-Net checkpoint on any road scene you upload — three panels (Input · Mask · Overlay) plus a per-class pixel-percentage table.Semantic segmentation is the perception layer of self-driving.
Every modern autonomous-driving stack does pixel-wise semantic segmentation somewhere in its perception pipeline — that's how the car knows what is road, sidewalk, pedestrian, sign before any planning happens. The Lyft / Udacity Carla challenge was a common benchmark that produced a wave of student-built encoder-decoder networks, most of which are public, many of which have subtly broken evaluation code. PixelDrive is one of those — but cleaned.
“The architecture consists of a contracting path to capture context and a symmetric expanding path that enables precise localization.”
“We employ an encoder-decoder structure with atrous spatial pyramid pooling to capture multi-scale context.”
“Build a semantic segmentation model for road scenes using Carla simulator data — 13 classes, vehicles, pedestrians, signs, road furniture.”
“Why is my mIoU stuck at 0.99 even when masks look wrong? — using sparse loss with one-hot inputs / wrong axis on argmax / etc.”
Fix the metric. Then pick the model honestly.
Audit, train, compare, ship.
The 7-bug audit.
First sprint was purely a correctness pass. Walked the data loader, the loss function, the metric, and the prediction pipeline against the standard formula for each. Found seven things wrong, three of which are the headline ones: the custom mIoU was computing pixel accuracy, the loss was softmax-of-softmax, and half the masks were read from the wrong RGB channel. None of these would have broken training; all of them would have broken the comparison.
Train three architectures end-to-end.
Same training loop applied to U-Net, SegNet, and DeepLabV3+. Class-weighted cross-entropy to fight the long-tail imbalance, light augmentation (flip + brightness), AdamW, cosine LR schedule. Trained each model to convergence on the same split. Recorded per-class IoU and mean IoU at the end of every epoch so the curves were comparable throughout, not just at the final epoch.
Pick + ship U-Net.
U-Net came out on top at 79.33% mIoU. Exported the best checkpoint (unet_best.keras), wrote a 90-line Gradio app that resizes to 256×256, runs inference, renders a three-panel figure (Input · Mask · Overlay) plus a class-percentage table, and deployed it as a public Hugging Face Space. Total deploy size: ~7 MB for the weights.
Before retraining anything, I ran the freshly-fixed mean_iou() on a hand-picked pair: a ground-truth mask against itself (must return 1.0) and against a uniform-class mask (must return ~1/13). Both checks passed; the metric was trustworthy. Only then did I touch the model.
From road photo to thirteen colored pixels.
The deployed inference path is intentionally short — five steps from upload to overlay. The training pipeline is more involved (three encoder-decoders, three training loops, three evaluation passes) but the inference surface is just the U-Net.
# Encoder — 4 down-blocks
x → Conv2D(64) → Conv2D(64) → pool ─┐
→ Conv2D(128) → Conv2D(128) → pool ─┤
→ Conv2D(256) → Conv2D(256) → pool ─┤
→ Conv2D(512) → Conv2D(512) → pool ─┤
│ skip
# Bottleneck │ connections
→ Conv2D(1024) → Conv2D(1024) │
│
# Decoder — bilinear up + concat skip │
→ up + concat(skip4) → Conv2D(512) <┘
→ up + concat(skip3) → Conv2D(256)
→ up + concat(skip2) → Conv2D(128)
→ up + concat(skip1) → Conv2D(64)
→ Conv2D(13, 1x1) # one logit / class
The Gradio Space ships at huggingface.co / mustakimfs / pixelDrive.
Anyone can open the Space, drop a road photo, and watch the three-panel output render — Input on the left, the colored segmentation mask in the middle, the input-mask blend on the right. A class-percent table underneath shows which of the 13 classes were detected and how much of the frame each one took.